 |
Machine Learning Overview (page 8 of 13) |
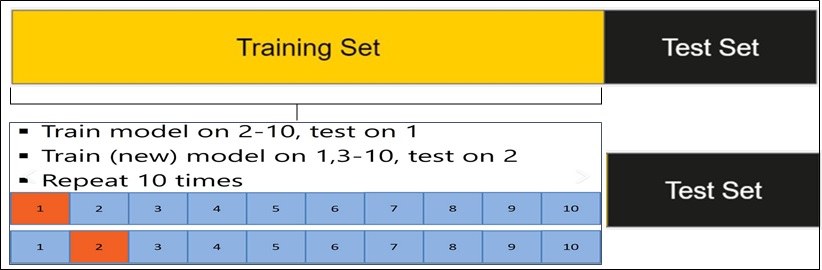
To construct a machine learning model with known targets (i.e., supervised machine learning problems), we have to train it. We do this by randomly splitting our data into a training and a testing data set. The model is developed using only the training data. We don’t touch the test data set (sometimes referred to as holdout data set) until we are ready to see how accurate our trained model is (i.e., evaluate the model's performance).
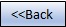
We may also further divide our testing data set into different groups (training and validation). This process is referred to as k-fold cross-validation. Cross-validation is typically used to improve model prediction when we have relatively small sample sizes and our randomization processes might not be sufficient by themselves.