 |
Machine Learning Overview (page 12 of 13) |
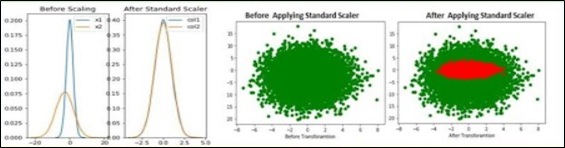
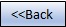
Data Scaling refers to the scale of our features.
Certain machine learning algorithms might only work well if all features have the same scale. For instance, a distance algorithm such as k-nearest neighbors will not work well if one feature has a scale from 0 to 100K and another feature has a scale from 0 to 1. A few of the common scaling options are the following:
Standardization: scaled to have a mean of zero & stdev of 1
Normalization: scaled to have a unit mean and variance
Range: scaled to span a defined range
Binarization: above a threshold scaled to True, otherwise scaled to False