 |
SGD Classifier and Regressor (page 7 of 9) |
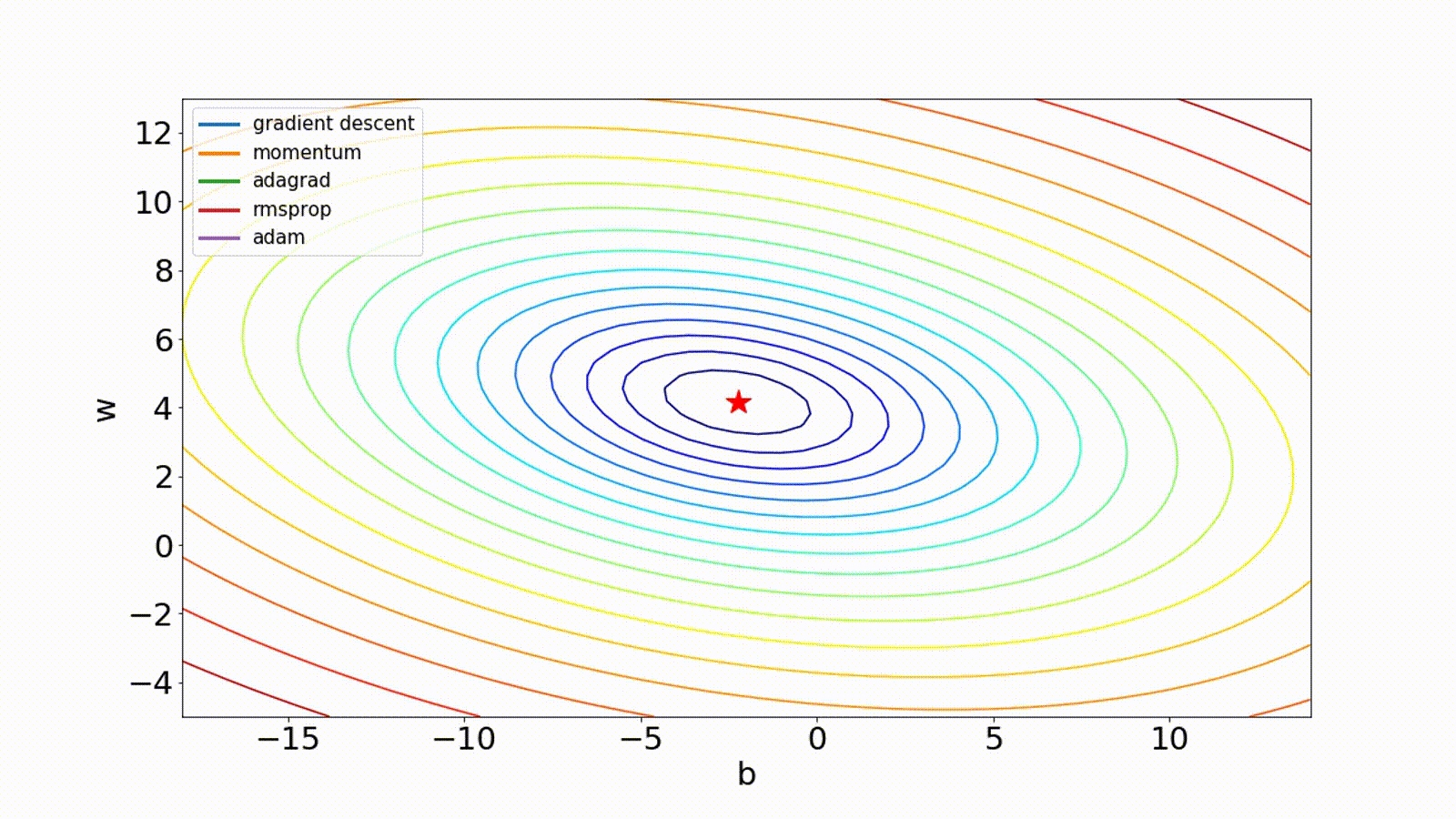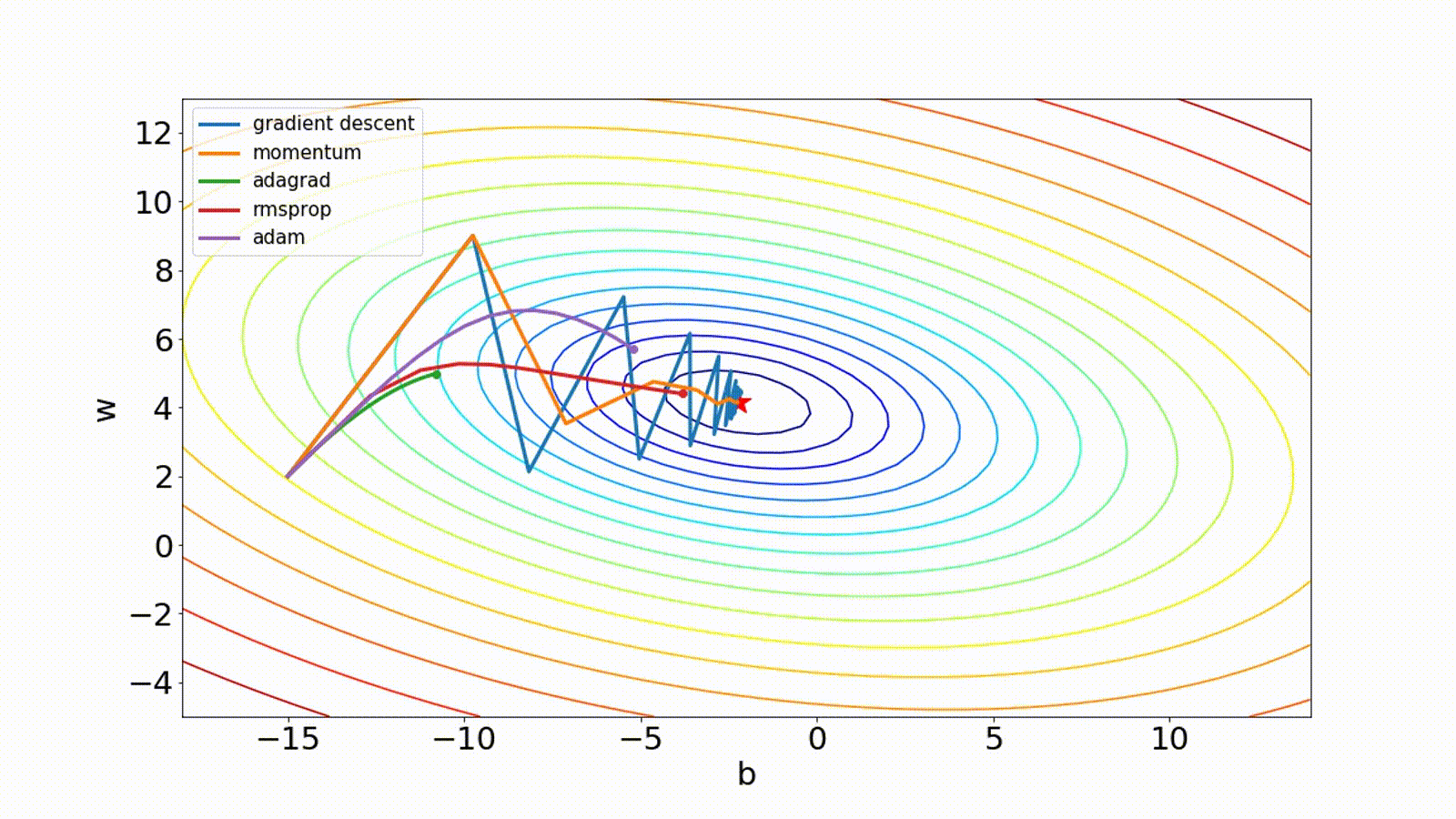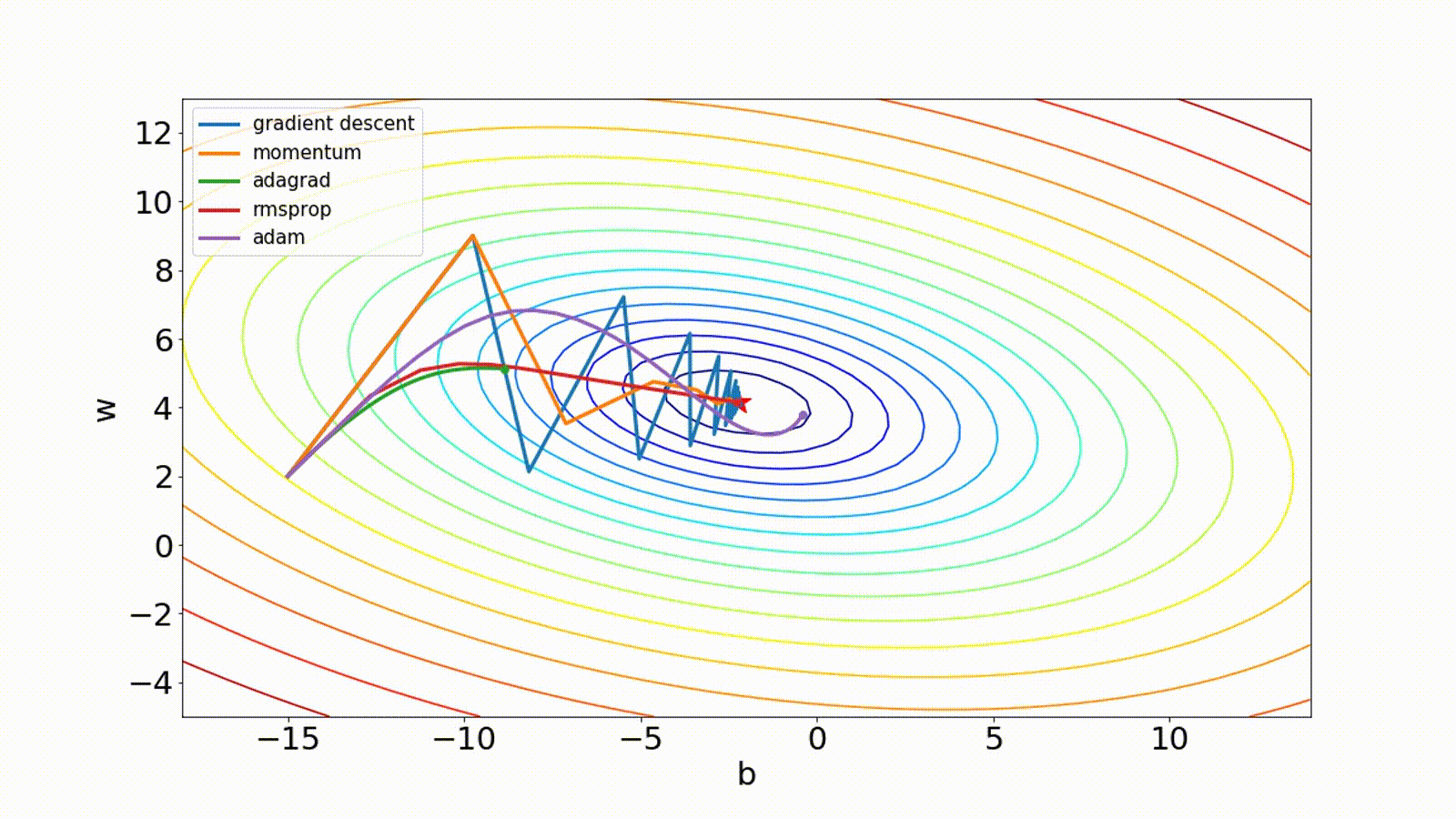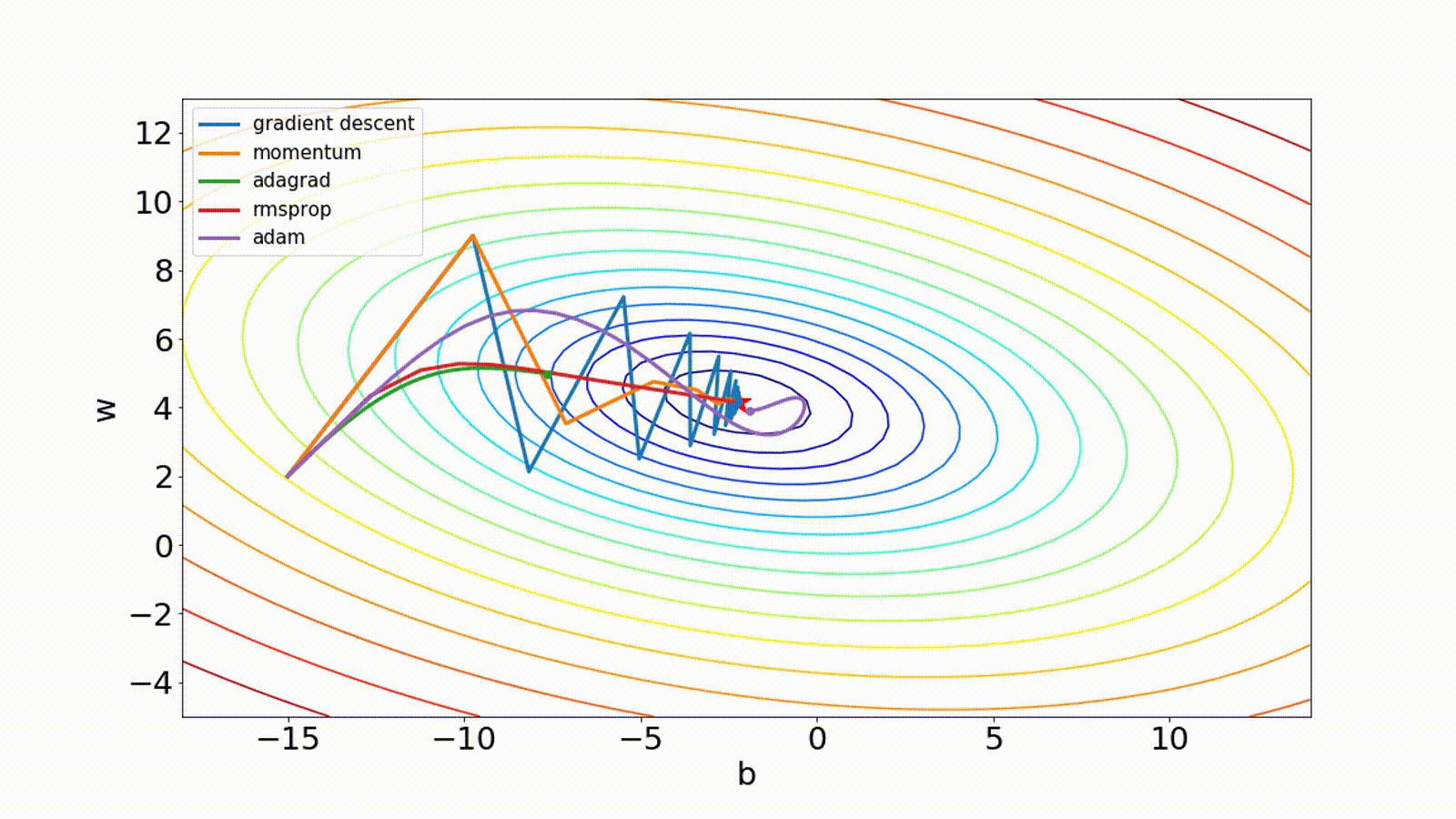
There are other optimization techniques. The Adam method computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients.
Momentum computes an exponentially weighted average of the gradients to update the weights, which can reduce the amount of oscillations seen in iterations.
Adagrad scales the learning rate for each parameter according to the total of squared gradients observed during training.
Msprop is similar to gradient descent with momentum except it restricts the oscillations in the vertical direction.